Most things on the web can be scraped and there’s many methods to do so, but did you know R has these capabilities? I’ve had a few folks ask me how and having automated the web scraping for Glassdoor company reviews with the gdscrapeR package, I’ll demo its usage as an example. Go straight here if you’re looking for the R package files.
=======
Analysts like to look out for interesting datasets as they browse the web. If we’re lucky, it’s neatly packaged and readily available, but that is hardly ever the case. HTML is in an unstructured format and no one wants to manually “copy and paste” into a spreadsheet to gather the data. I admit I’ve done this plenty of times before and I hope not to ever have to again.
Enter web scraping
Web scraping is a technique of automatically mining information from a website. It’s a way to build your own dataset that doesn’t involve cramped fingers from Ctrl+C and Ctrl+V. I think all skilled data analysts should have some scraping tools because there’s so many possibilities in harvesting an abundance of data from the wide open spaces of the Internet.
“Why not use the API instead of scraping,” you ask?
Great question. Although most websites are developer-friendly and provide an Application Programming Interface (API) for obtaining data, there are various reasons why it may not be a better option over web scraping. In this case, the answer is simple - Glassdoor has an API available, but not for the contents I’m after: the company reviews.
Scraping demo
Let’s say we want to scrape text data from the company reviews for SpaceX.
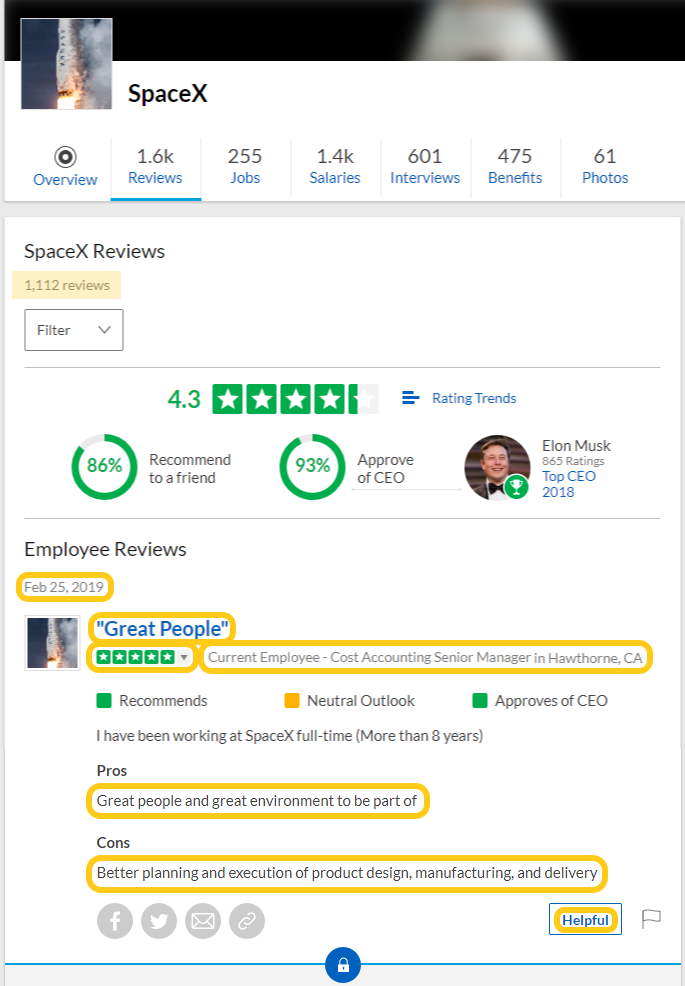
The company currently has 1,112 total reviews, so with 10 reviews per results page, we’ll be scraping across 112 pages for the following:
Date - of when review was posted
Summary - e.g., “Great People”
Rating - overall star rating between 1.0 and 5.0
Title - e.g., “Current Employee - Manager in Hawthorne, CA”
Pros - upsides of the workplace
Cons - downsides of the workplace
Helpful - count marked as being helpful, if any
We just need to note the company’s unique Glassdoor ID number, which is found in the URL. It’s identified as all the characters between “Reviews-“ and “.htm” (usually starts with a letter(s) and followed by up to seven digits). For SpaceX, the company number in “www.glassdoor.com/Reviews/SpaceX-Reviews-E40371.htm” is “E40371”. Now, we can get these text data into a table with a few lines of code using gdscrapeR:
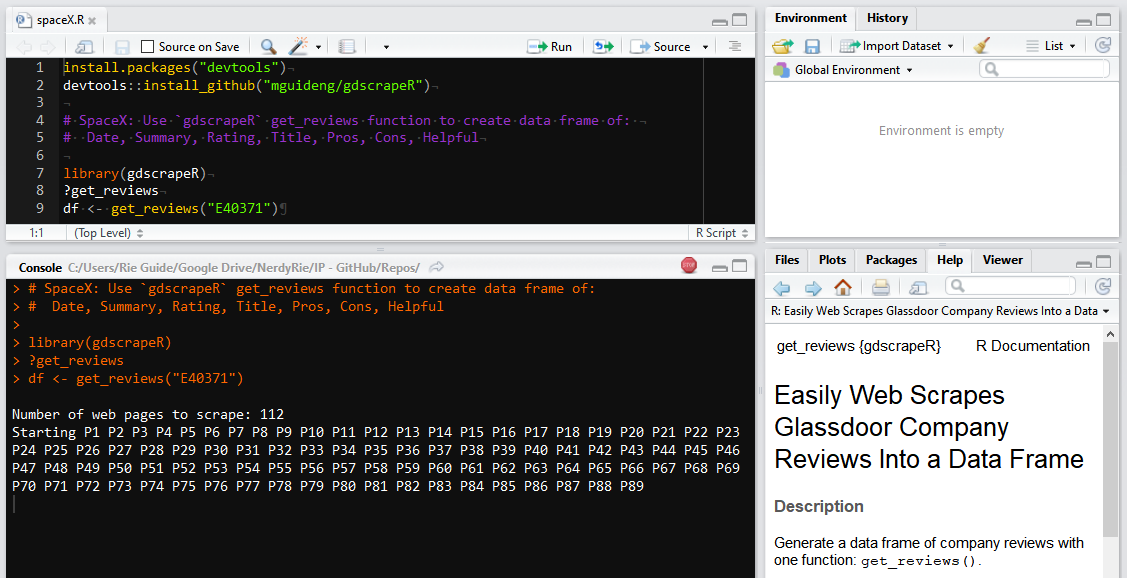
Whoa. What’s going on here? One moment, I was data-less, and then a few minutes later, BOOM! - a table appeared.
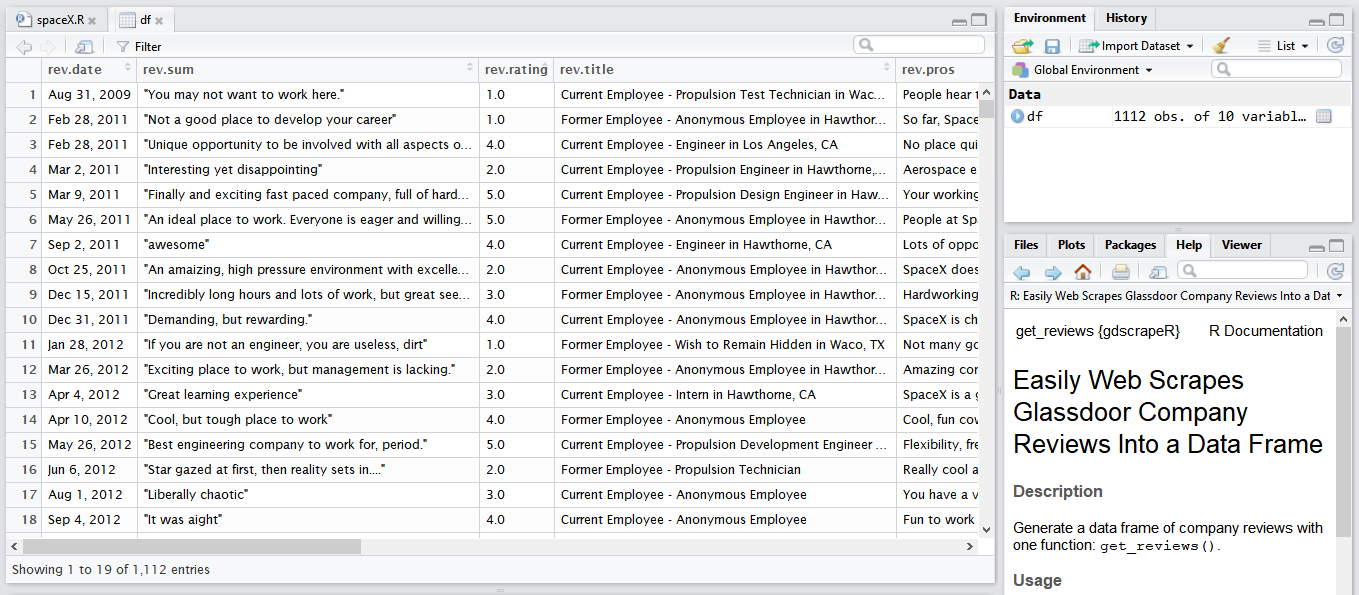
We now have a dataframe with 1,112 rows - one for each reviewer - that can be exported to a CSV file. Is this some sort of magic??
Nope, it’s gdscrapeR!
The gdscrapeR scraper uses one function - get_reviews() - and you pass the companyNum parameter through it. Easy, right? Well, when we decompose it, we’ll see that it’s basically just a wrapper function for other packages that do all the heavy lifting to make the scraping process easy through an HTML parsing method. Specifically, it relies on the rvest, httr, xml2, and purrr packages.
Here’s an “unwrapped” version of the function’s code gist that will get the same results.
Before we go over what’s going on here, there’s two things we have to figure out: 1) how the data can be accessed, and 2) how the data is structured in HTML.
1) Accessing the data
The first line of order is to know how to access the data online. I explored how the URL changed as I clicked through the page results and applied different sorting. The landing page will be: www.glassdoor.com/Reviews/SpaceX-Reviews-E40371.htm and it includes the first 10 results. Clicking to page 2 changes the URL so that “_P2” is added towards the endpoint. With 1,112 total reviews (and no option to increase the number of results per page), I figured results would max out at “_P112” (i.e., round 1,112 up to the tenth which is 1,120 / 10 = 112). To confirm this, I changed the URL directly and that is indeed where the last review falls off. This is shown in the R code as maxResults.
As for the sort, the landing page defaulted by most “Popular”. What happens when I change the sort by clicking on “Date”? The URL changed to www.glassdoor.com/Reviews/SpaceX-Reviews-E40371.htm?sort.sortType=RD&sort.ascending=false&filter.employmentStatus=PART_TIME&filter.employmentStatus=UNKNOWN. I then changed the “sort.ascending” parameter from “=false” to “=true” since I wanted the oldest reviews first.
All the extra parameters regarding the employment status filters were omitted since results default to displaying regular and part time workers (which is what I wanted) when they are not specified in the URL. In the R code, baseurl, companyNum, and sort will fetch only what is necessary in order to load the pages that will access the data.
As you navigate through the website to identify the data of interest, it will be helpful to:
- formulate how the data output will be organized (e.g., type of sort);
- figure out whether you’ll be applying filters for a subset of the results (e.g., only full-time workers); and
- pay attention to how the URLs change in the process.
2) HTML data structure
Now here’s the tricky part (for me at least). In understanding how the data is structured and how the page is displayed in a browser, knowledge of Hyper Text Markup Language (HTML) and Cascading Style Sheets (CSS) is a big advantage. HTML can be considered the building-blocks of a webpage whereas CSS describes how HTML elements should be presented (e.g., font size, color, type; styling around images; layout).
If you’re already a pro and know all this stuff, you can skip to the next section. Otherwise, take a look at this snippet of the HTML document that generated the Glassdoor page from the screenshot above:
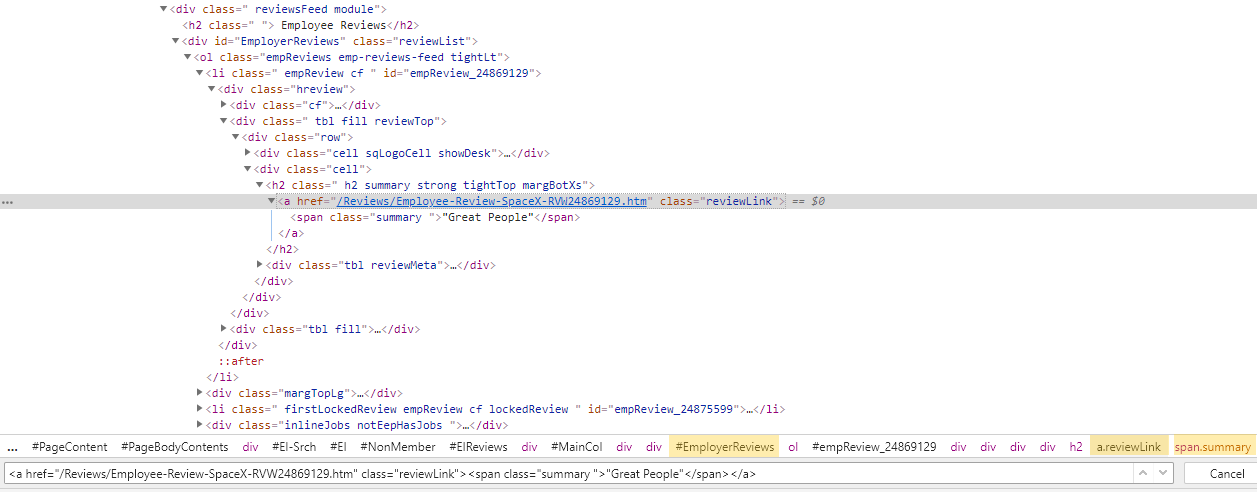
This is accessed through Chrome DevTools by pressing Ctrl+Shift+C from the webpage. Since it looks like something my (very smart) cat would’ve typed out by walking across my keyboard, the tricky part was extracting the data out of it. All the text I want is in there somewhere. I just need to identify the right HTML elements to select. HTML elements are enclosed within start and end tags, indicated by the angle brackets. The important thing to understand here is that we can use what’s called CSS selectors to “select” the HTML elements we want based on their element class.
For instance, the snippet contains the summary text “Great People”, along with its element tags. This particular <span></span> tag has a class attribute with a value of summary, anchored within the <a></a> tag with a class attribute of reviewLink. The syntax to describe the elements with class=”summary” within class=”reviewLink” requires a dot (.) character followed by the class name: a.reviewLink span.summary, which can be shortened to .reviewLink .summary. If we were to search for this selector pattern by pressing Ctrl+F, we’ll see that there’s 10 matches. Great - that’s what we want. Actually, we also want to find the shared common structure and consistent patterns in selectors for each of the variables across all 1,112 reviews.
Go Go (Selector)Gadget
Want a work-around for inspecting the HTML document? No problem. We can rely on the SelectorGadget tool to start identifying the CSS selectors for us. This point-and-click tool compliments the use of the rvest package (both created by R expert Hadley Wickam), which will be used together with our class selectors. Make sure to check out how they work together here because it will do a better job at explaining this process (and provides info on using XPaths as an alternative to selectors). Go ahead!

Ok, so here are the class selectors for the variables:
Total reviews = .tightVert.floatLt strong or margRtSm.margBot.minor or .col-6.my-0 span
Date = .date.subtle.small and .featuredFlag
Summary = .reviewLink .summary:not([class*='toggleBodyOff'])
Ratings = .gdStars.gdRatings.sm .rating .value-title
Title = span.authorInfo.tbl.hideHH or .authorInfo
Pros = .description .row:nth-child(1) .mainText:not([class*='toggleBodyOff']) or .mt-md:nth-child(1) p:nth-child(2)
Cons = .description .row:nth-child(2) .mainText:not([class*='toggleBodyOff']) or .mt-md:nth-child(2) p:nth-child(2)
Helpful = .tight
Back on track to the scraping demo
Now that these are identified, we can take a look at how they were used with the functions in rvest and the other packages in the code gist. These will be limited to those that gdscrapeR depends on, so refer to the packages’ documentations to explore more options. Also, note that the pipe-operator %>% was used to make the code easier to read and understand by coupling the functions in order of execution.
-
httr::GET()to get the glassdoor.com URL page by making a request to the server to respond with an HTML file. The source URL is specified bybaseurl,companyNum, andsort. -
xml2::read_html()to convert the HTML document into XML objects called nodes (or nodesets). Think of the HTML document as if it were a bunch of node objects representing the document’s contents. It is stored as'pg'in R’s environment after it passes through GET(). -
rvest::html_nodes()to select parts of the XML object nodes based on the class selectors. The stored results for the variables will be lists of the node objects and their tagged attributes. -
rvest::html_text()andrvest::html_attr()to extract only the text portions from the tagged nodes. -
purrr::map_dfr()to bind together the rows of text from each page result (i.e., 10 rows from P1 + 10 rows from P2 + … + 2 rows from the maximum P112) and create a single data frame. The default is to convert strings to factors so using thestringsAsFactors = Fparameter will suppress this to keep them as character vectors.
A note on map_dfr(): this function combines all rows from the variable columns (e.g., rev.date, rev.sum, rev.rating, and so on) into a single data frame by row binding when used with gdscrapeR. A data frame has a rectangular structure where the number of rows are the same length (and same with columns). In this example, each column will have 1,112 observation rows based on totalReviews. I don’t see why the number of rows should differ, provided a suitable pattern of CSS class selectors are applied. However, there can be limitations.
Known limitations: Changes to the Glassdoor site
Layout updates and new feature implementations will change the HTML structure of a website. Thus, a common issue with scraping is the need to keep up with the changes made to a website’s pages. For the Glassdoor site, I’ve seen different versions of the same page on occasion. This is possibly due to A/B Testing (also known as split-run testing), which is an experiment where two or more different versions of a page are shown to visitors at random to determine which one(s) perform most effectively for a targeted conversion goal.
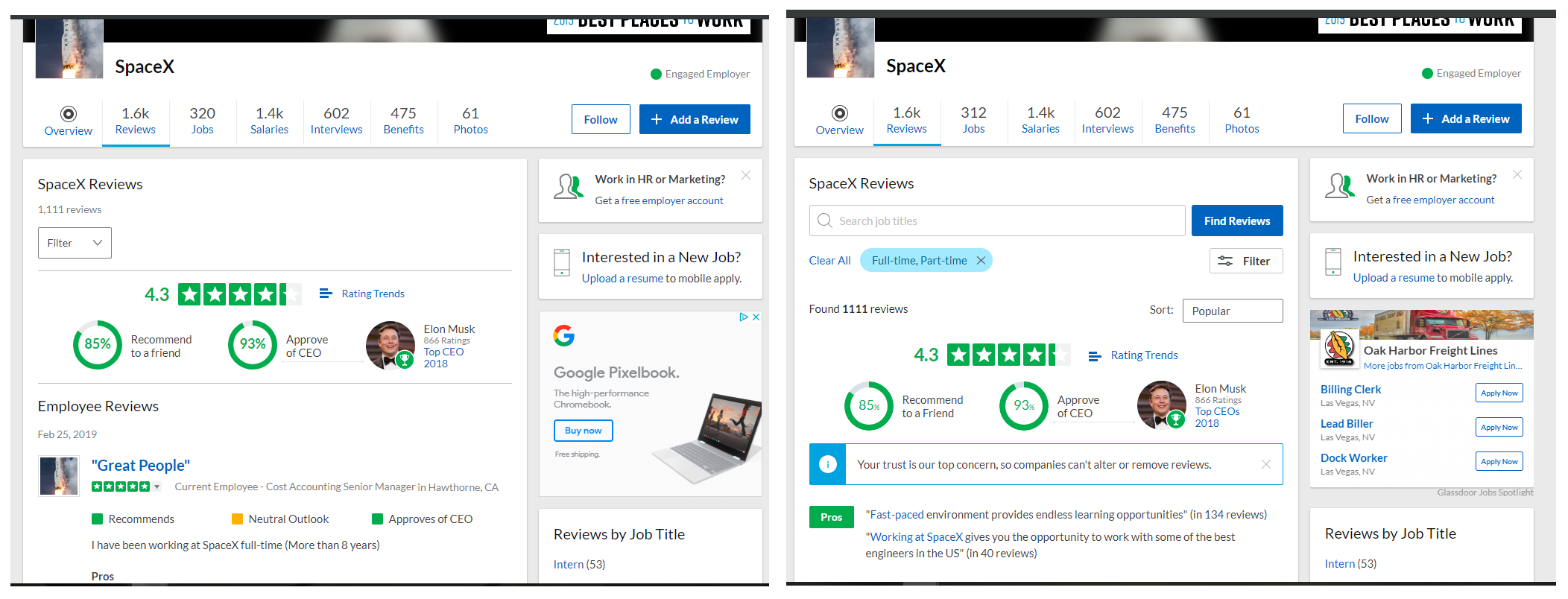
It’s obvious by now that getting the data we want requires selecting the right elements, so different selectors due to changes will return a null (or differing) number of rows. In these cases, using gdscrapeR will throw an error shown as “Could not scrape data from website.” This is because at least one of our variables returned an inconsistent row length (e.g., 0 or 1,111 instead of 1,112) and therefore did not meet the condition for map_dfr() before it can row bind.
Solutions
Try gdscrapeR again at a later time with a new session to get the split version of the website that will work.
If that doesn’t do it, a user-friendly (though verbose) workaround in the meantime is to copy and paste the unwrapped code gist above into an R script file you can work with. Run the code chunks for each variable separately to identify which one(s) changed. It will return a dataframe that is null or differs from the value specified by totalReviews. Use SelectorGadget or Chrome’s DevTools to inspect and identify alternative selectors to pass through rvest::html_nodes() that return the correct number of observations.
This requires trial and error so if you’re not a unit testing / test integration person, that’s too bad. You’ll become one if you wanna web scrape. You are welcome to contact me for maintenance [imlearningthethings at gmail] and feel free to make pull requests via GitHub to share your solutions!
Alas, it’s ready for text analytics
After successfully scraping the text from the company reviews and combining them into a single tidy data frame, regular expressions can be used to create additional variables.
Since most of this text information is character data, rather than numerical or factor data, this dataset is better suited for text analytics areas such as applying Natural Language Processing techniques (e.g., tokenization, lemmatization) for concept extraction (e.g., topic modeling, sentiment analysis, and examining the frequency and relative importance of words). I highly recommend the “Text Mining with R” book by Julia Silge and David Robinson for inspiration and ideas.
=======
Learning points
-
SelectorGadget helped to identify the selectors to pass through
html_nodes(), however it had its limitations. It was picking up additional elements that were hidden (due to toggling between English and foreign language translations for a few reviews) and could not be deselected by the point-and-click tool. I couldn’t figure out how to exclude them without manually reducing the output. So special thanks to my friend Kirk N. for poking around the HTML source code to provide a solution, which was to add the:not([class*='toggleBodyOff'])specification. -
Writing a scraper is fun, challenging, and opens up so many possibilities for data analysts and data scientists. Although most everything on the web is scrapable, there are restrictions and it may not be completely allowable (particularly if you create an account that requires a log-in). You can check a site’s restrictions (which can often be found by adding “/robots.txt” to the end of the website URL) before deciding what/how to scrape and what you’ll be doing with it.
-
A best practice for web scraping includes not overloading web servers and allowing reasonable time gaps in between each sequential scrape. This is an important point. Aside from not wanting to have your scraper booted, it’s just not polite to bombard servers with hundreds/thousands of immediately sequential requests.
gdscrapeRis set to sleep ~5.5 seconds (on average) in between each iteration. For a well-behaved bot, I would suggest allowing 2 seconds minimum (or 5 seconds ideally) between each page request. -
Going the API route involves registering with a site administrator to get a key and to make requests using that key. Depending on my specific needs, an API may be the better option over writing a scraper that makes HTTP requests, especially since keeping up with changes to a website requires constant maintenance to a scraper. There can be reasons, however, why an API is not sufficient for your needs. Aside from lack of availability, what other reasons might one opt to bypass it? Consider the following scenarios:
- The API available may not be as up-to-date as the visitor webpage itself and you are depending on current data;
- Rate limits are more restrictive than your (polite) web scraper and you don’t want to be subject to them;
- You simply want to gather data privately while remaining anonymous; or
- Just because it’s a project you’ve been wanting to do. In that case, happy harvesting!
Notes
- Updated post to replace “It’s Harvesting Season - Web Scraping Ripe Data” (August 1, 2018).